迈向通用领域的数据评估
1
2
这篇工作依旧在施工中。
不一定保持线性更新,可能这篇工作写到一半会更新其他的工作。
这篇文章的主题叫做”迈向通用领域的数据评估”,目前,LLM+RL的方法在许多领域,尤其是数学和代码上都取得了能力上的突破。然而在除了数学和代码这两个具有ground-truth answer的领域外,如何评估通用领域数据的质量,成为了一个重要的问题。在这里,数据质量评估其实有两重含义:1. 在训练时评估数据的质量,这是为了选取不同质量的数据,从而对模型进行预训练/监督微调/强化学习等方法提高模型能力;2. 在benchmarks中评估数据的质量,这是为了评测模型在某一任务上的表现。为了让读者理解这两个含义,我们用一个例子来解释:
PM表示,希望算法部门增强LLM的心理支持能力。这里面涉及到这些问题:
1.如何筛选构建高质量的心理支持对话数据集,让模型通过监督微调/强化学习等方法来提高对心理支持对话场景的理解?
2.在训练模型后,如何构建benchmarks数据来评估模型的心理支持能力?怎么保证benchmarks的ground-truth是唯一正确的?
3.在评测模型的时候,应该采用什么样的指标来评估模型的心理支持能力?如果确定了指标,或者让LLM-as-a-judge来进行评测,应该如何证明这些方法真实反映了模型的能力?
这个例子涉及到很多问题,但在这个blog中,我们首先阅读两篇关于1和2问题的papers。
1. 北理、小红书:LLM-Powered Benchmark Factory: Reliable, Generic, and Efficient
gaps: 目前构建benchmarks大量依赖与人类提供的信号,而现有LLM-generated Benchmarks则依赖于已有的种子benchmarks data和具体的task design,因此缺少在任务和领域上缺乏泛化性;并且,目前缺少对于benchmarks的评估框架,这削弱了LLM-generated benchmarks的可靠性。
contribution: (1) 利用因果学习的方法,识别和确认了benchmarks应该具备的10个标准,并据此构建了一个自动针对benchmarks的评估框架。(2) 在此基础上,分析了LLM作为benchmarks generator的优势与不足。(3) 构建了一个通用的benchmarks generator BenchMaker,其采用stepwise self-correction和conflict guided contrastive discrimination来增强忠实性 (faithfulness);采用difficulty strategy guidance和difficulty diffusion mechanism来拓展数据集的难度 (difficulty);并通过AttrPrompt和in-batch redundancy filtering来提高数据的多样性 (diversity)。
1.1. Benchmarking Benchmark Generator
相较于训练数据,评测数据由于存在基准答案 (ground-truth answer),因此需要更为全面的质量评估以确保这些answers的可靠性 (reliability)。作者团队首先构造了10个指标,用于评估benchmarks的性质:
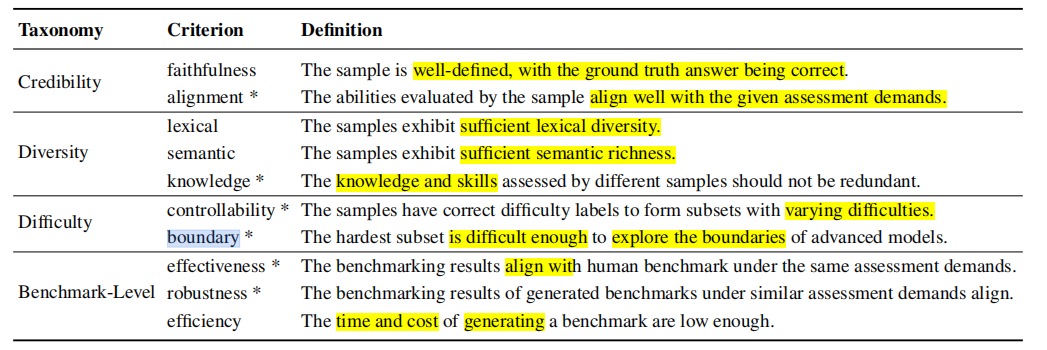
Credibility:
- 忠实性 (faithfulness): 数据应该被良好地定义,其ground-truth应该是正确的。
- 对齐性 (alignment):数据评估的能力应该和评估要求能够良好地对齐。
之前的benchmarks主要依靠人工评估或LLM-as-a-judge来确保上述两个要求,然而,前者无法自动化,后者则存在bias。为了缓解LLM-as-a-judge存在的bias,作者采用Qwen-Plus作为judge model来探索LLM-as-a-judge的bias。实验显示,忠实性和对齐性受到多个因素的显著影响,具体而言:
- 对于忠实性,更长的分析会提高judge error出现的概率。
- 对于alignment,更长的分析会提高alignment的正确性。
- 在控制分析长度后,其他因素对judge model的影响不再显著。
因此,judge分析的长度直接影响着模型的bias,因此,对于每个评估的benchmarks generator,作者采用多元回归模型设计了一个unbiased judge results: \(f(i) = \beta_i + \beta_{\text{len}} \cdot \text{judge\_length} + \epsilon\) 其中,$\beta_i$表示模型输出的分数,$\beta_{\text{len}}$表示协变量,例如假设$\beta_{\text{len}}=-0.02$,gpt-4o评分是8,长度是150 words,那么修正后的分数就是$8-0.02 \times 150=5$。参数通过对已有数据构建多元回归模型得到。
- Diversity:
- lexical: 数据应该展示足够的词汇多样性。传统的指标一般是词汇数目或self-BLEU, 但他们可能会受到数据长度的影响。作者采用unbiased word frequency entropy来评估lexical diversity。
- 语义性 (semantic):数据应该展示丰富的语义丰富度。作者采用Embedding模型来对数据进行嵌入,然后计算各个语义之间平均欧几里得距离来衡量语义丰富度。
- 知识性 (knowledge):不同样本的评估的知识与能力不应该冗余。如果不同数据测试的子能力相同,那么模型在这些数据上会表现类似的正确性模式(可以理解为对这些知识的representation)。对于一个数据,其知识嵌入由多个模型对这个数据的表示组成。如果不同数据的知识嵌入很接近,就说明他们测试的子能力非常一致。
- Difficulty:
- 控制性 (controllability):数据应该有正确的难度标识,从而组成具有不同难度的数据集。难度可控性通过实际难度标签的Spearman相关系数进行测量,多个模型的平均错误率作为样本的实际难度标签,与benchmarks提供的难度标签进行比较,计算二者之间的Spearman相关系数。如果相关系数较高,则表示生成的样本难度划分较为准确。
- 边界性 (boundary):最难的一部分数据应该足够困难,以探索最先进模型的能力边界。作者通过测量在最困难子集上的模型的平均错误率来评估其难度边界。高错误率意味着这个子集的题目对当前模型的能力来说是具有挑战性的,能够有效帮助区分模型的能力水平。
- Benchmarks Levels:
- 有效性 (effectiveness):对比人类构造的benchmarks,评估的结果应该相同。 通过计算在generated benchmarks和human benchmarks上,多个模型的准确率之间的Pearson correlation来衡量。高相关性表明生成的基准在评估模型能力方面与人工基准一致。
- 稳定性 (robustness):对于相似评估要求的问题,其评估的应该相似。在相似的评估需求下(例如,原始需求和经过GPT-4o重写的需求),generated benchmarks计算多个模型在这些基准上的准确率,然后计算这些准确率之间的皮尔逊相关系数。高相关性表明生成的基准在不同输入下具有一致性。
- 高效性 (efficiency): 生成一个benchmarks的时间和成本应该足够小。通过计算API调用成本和时间来分析。
1.2 Development of BenchMaker

(1)格式选取:作者选取多选问题(multiple-choice questions, MCQs)作为主要的数据格式。
(2)直接Prompting的优缺点:作者选择MATH,MMLU-Pro,HellaSwag作为对比的高质量人类benchmarks,然后采用GPT-4o mini作为生成模型来生成数据集。结果显示,直接prompt生成的数据集具有更弱的忠实性,更低的语义多样性,以及更少的challenging数据。但是,直接prompt LLM生成的数据集对齐性更高,具有更多的知识性多样性,并且在高效性上要更好。
(3)忠实性优化:Stepwise Self-correction. 作者让模型在每个生成的step中验证内容,如果错误被检测到,那么模型就会返回最开始的内容。相较于整个sample的checking,step-wise的检查提升了错误的检测率。Conflict Guided Contrastive Discrimination. 在Self-correction中,模型除了要判断是否有错,还需要多次生成答案。对于多个答案,模型需要检查是否存在冲突,然后对比推理过程哪个更合理,最后做一个最终决定选择哪个作为benchmarks data。
(4)困难性优化:LLM有一些能力去感知问题的困难性,但本身非常弱。因此,作者让LLM在生成问题后,会再次扮演测试者的角色来回答问题。模型对问题的回答错误率被用于作为该问题的难度标记,从而提高数据的controllability。除此之外,作者还采用了2个方法:1) Difficulty Diffusion Mechanism. 将已生成较难的数据作为参考样本,使用这些参考数据指导模型生成新的数据,并且要求新样本的难度要比参考样本更高。通过这种方式,样本的难度可以逐步扩散和提高。在这个过程中,为了避免参考样本过于固定,引入了动态调整策略(例如随机选择样本+打乱顺序),以保持生成样本的多样性。
2)Difficulty Strategy Guidance. 根据不同任务的特点,提供生成不同难度样本的策略。例如数学问题的策略是生成更多复杂信息的题目等。在生成过程中,通过逐步引入这些难度策略,样本的难度会随着生成过程的推进而增加。模型可以被要求生成不同难度级别的样本,并提供具体的策略指导,比如增加问题的复杂性、引入更多的干扰选项等。随着策略的不断引入,benchmarks data会越来越难,最后逐渐拓展题目的boundary。
(5)多样性优化:作者采用AttrPrompt和In-batch Diversity Boosting的方法,前者已经被广泛使用,其通过随机分配预生成的属性和值对作为每个样本的输入的一部分,明确增强benchmarks的词汇和语义多样性。这一策略确保生成的数据在结构和内容上更加丰富。后者则是在生成过程中,模型会生成多个候选数据,然后选择与输入参考数据在词频熵差异最大的一项。这种方法有助于避免生成的样本之间出现同质化,从而提升数据的多样性。
1.3. Experiment
在实验中,作者选用MATH, MMLU-Pro和HellaSwag这三个人工标注的数据集作为示例,每个数据集随机生成500个示例: 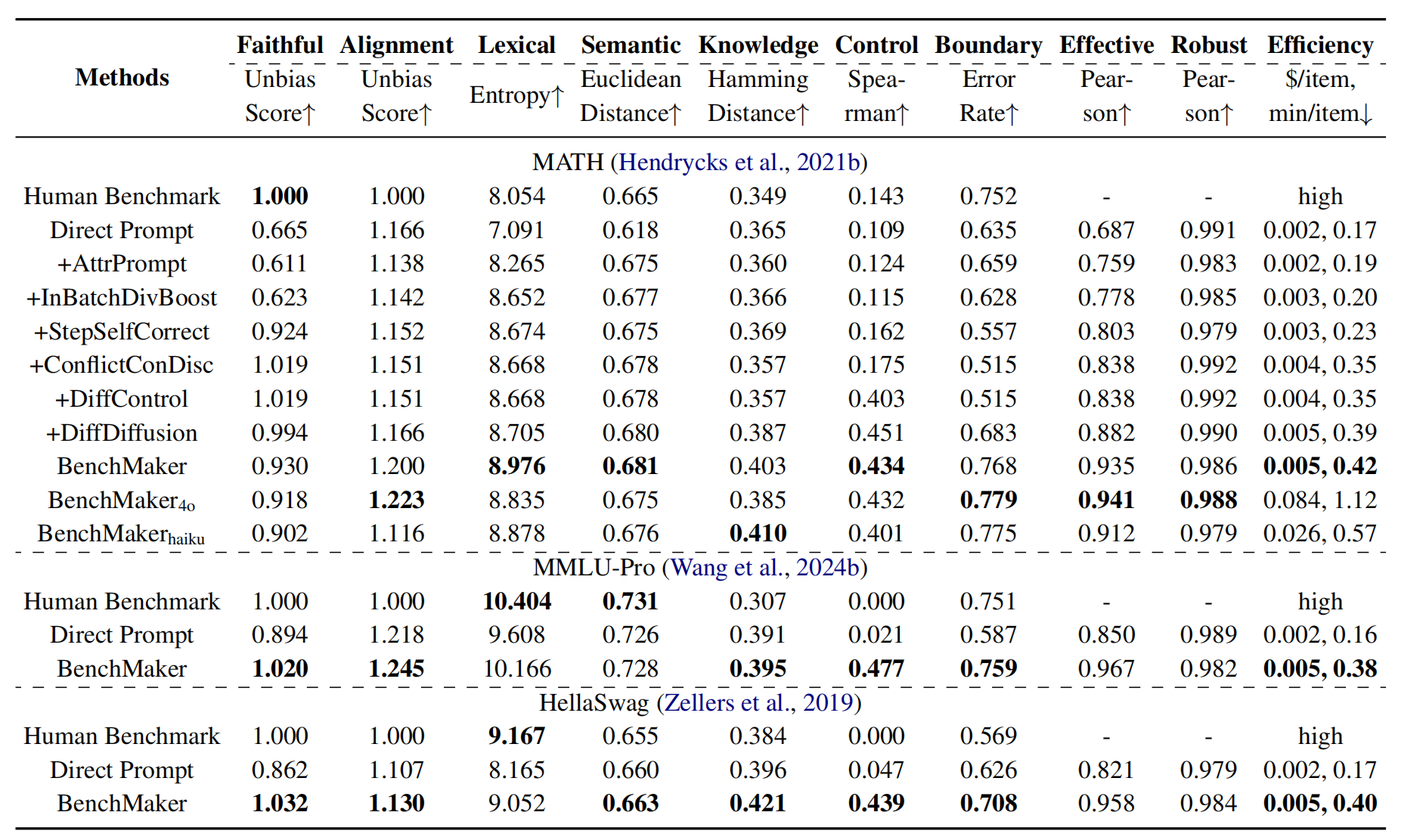
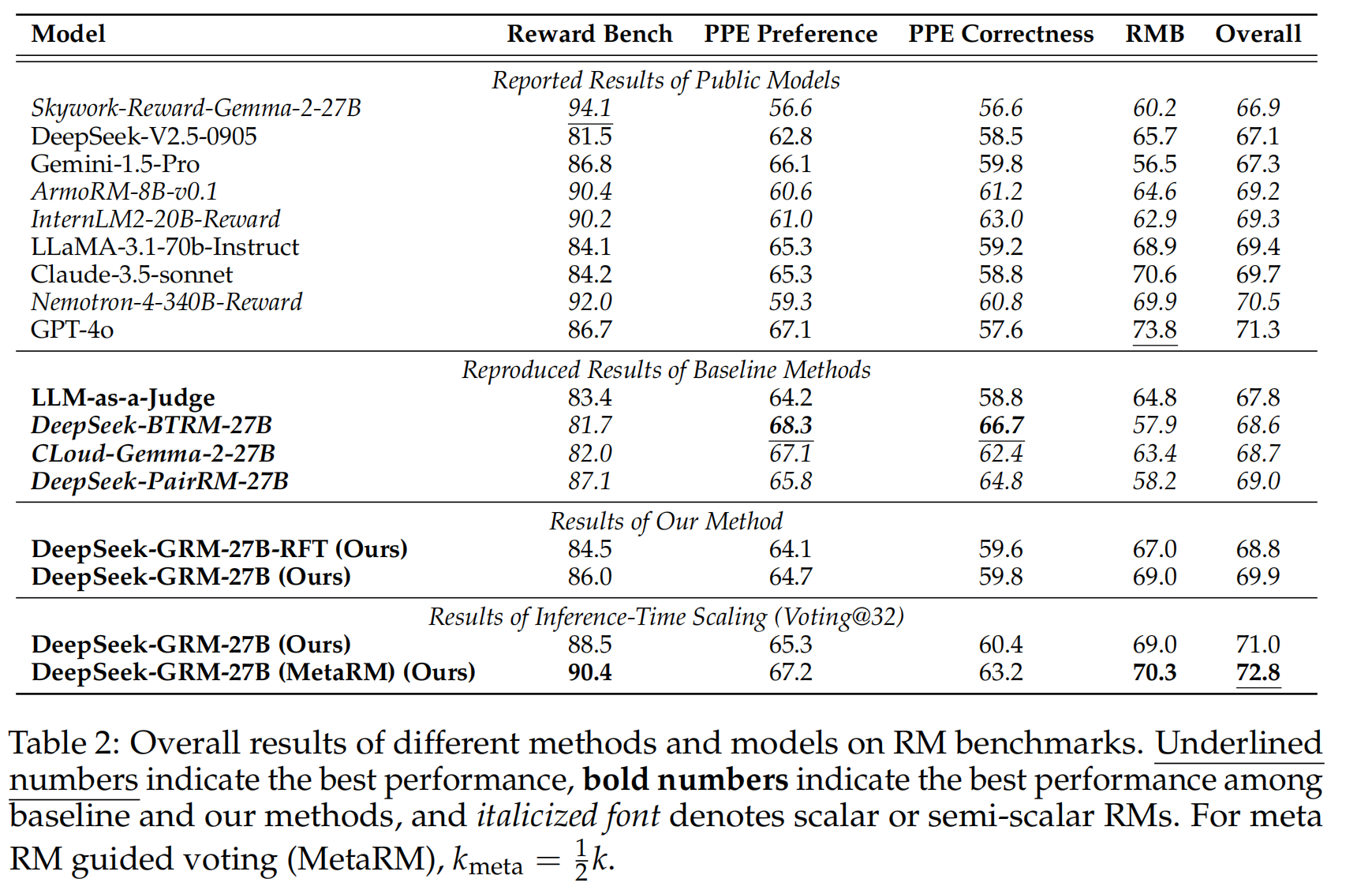
2. Deepseek: Inference-Time Scaling for Generalist Reward Modeling
gaps: RL在LLMs中起到了显著的效果,然而目前,高质量的奖励主要源于人类设计的具有明确条件的环境,或针对可验证问题的手工制定的规则(例如数学、代码)。在一般领域中,奖励生成更具挑战性,因为奖励的标准更加多样和复杂,而且往往没有明确的参考或真实依据。并且,对于通用奖励模型,其输入可能是多样的(单一/成对等),领域也是不同的。在这篇paper中,作者主要关注这个研究问题:能否设计一种学习方法,来为通用奖励建模实现有效的Inference-Time Scaling?
Contributions: (1)调研了不同类型的奖励模型,发现pointwise类型的GRM可以统一单一/成对/多组回答的评分。(2)提出了自原则批评调整(SPCT),让模型能够根据输入查询和响应自适应地提出原则和批评,从而在一般领域中获得更好的结果奖励,并训练了一个27B的参数模型(DeepSeek-GRM)。(3)引入了一个元奖励模型(meta RM),以在投票之外有效提升DeepSeek-GRM的推理时扩展性能。
0.(阅读之前)Reward Model & LLM-as-a-judge
Reward Model和LLM-as-a-judge分别在训练和推理阶段给予数据质量评测,前者对训练数据进行打分和比较,从而让模型进行强化学习;后者则对模型生成的数据给予打分或比较,从而评估模型的能力。
然而,在评估的粒度上,Reward Model能够给予token-level的信号,即其能够对文本中的每个token进行细粒度的评估。RM可以在生成过程中为每个token分配奖励值,反映该token在当前上下文中的质量。这种细粒度的反馈可以帮助模型在生成每个词时进行优化。
而LLM-as-a-judge则是提供Seq-level的信号。LLM-as-a-Judge 可能会对一段文本的整体逻辑性、语法正确性或是否符合任务要求给出一个评分。这种评分通常是一个单一的分数或比较,针对的是整个输出,而不是其中的每个token。
1. 基础

作者首先发现,高质量评判往往依赖于恰当的”原则”(principles)指导。初步实验显示,当使用经过筛选的合适原则时,GPT-4o在Chat Hard测试集上的准确率可从76.1%提升至77.8%,而Gemma-2-27B-it模型则从59.1%跃升至68.0%。然而,如果是自我生成的原则来指导评分,反而会使得其准确率出现一定下降。这激发了研究者探索如何让模型自主生成和运用正确的原则,从而在通用领域实现更可靠的奖励建模。
2. Self-Principled Critique Tuning:SPCT
\[\{p_i\}_{i=1}^m \sim p_\theta(x,\{y_i\}_{i=1}^n), \mathcal{R}=C\sim r_\theta(x,\{y_i\}_{i=1}^n,\{p_i\}_{i=1}^m)\]其中,x表示输入的input,y表示多个responses。$p_\theta$表示根据input和responses动态生成当前m条principles,然后基于input, responses和principles给出最后的reward。在这里,原则生成和提供奖励的模型是同一个模型$\theta$。
SPCT包括两个部分:(1)通过rejective fine-tuning进行冷启动;(2)通过rule-based online RL来提高GRM生成的原则和评分。
rejective fine-tuning
采用人工标注数据+预训练RM的采样,来微调模型。在这个过程中采用双重拒绝策略:排除预测reward与ground-truth不符的轨迹,以及所有评判都正确的”过于简单”样本。并且,在这个过程中,部分领域数据使用1次提示采样(Hinted Sampling),即在prompt中加入ground truth信息,让模型更好理解。
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
x: 请解释什么是机器学习,并提供一个简单的例子。 y1: 机器学习是一种人工智能的分支,它通过数据训练模型来预测或分类,而不需要明确的编程。例如,垃圾邮件过滤器通过学习标记为垃圾邮件和非垃圾邮件的电子邮件来识别新邮件是否为垃圾邮件。 y2: 机器学习是计算机科学的一个领域。我不知道具体是什么,但它与数据有关。 ground-truth (人工标注): Response 1 是更好的响应(评分 8),Response 2 是较差的响应(评分 3)。 采样RM: 采用Deepseek-v3,针对上面的进行采样,假如采样次数N=3: 采样1: 原则: - 内容准确性(权重:40%):响应是否准确解释了机器学习。 - 示例清晰度(权重:30%):是否提供了清晰的例子。 - 语言流畅性(权重:30%):响应是否易于理解。 评论: - Response 1:内容准确,提供了垃圾邮件过滤器的例子,语言流畅。 - Response 2:内容不准确,未提供例子,语言简单但不完整。 预测奖励:Response 1: 评分7, Response 2: 评分2 与 ground truth 一致(Response 1 更好),因此该轨迹被保留。 采样2: 原则: - 信息完整性(权重:50%):响应是否准确解释了机器学习。 - 相关性(权重:50%):响应是否与查询相关。 评论: - Response 1:信息较为完整,但可以更详细。 - Response 2:信息不完整,但与查询相关。 预测奖励:Response 1: 评分6, Response 2: 评分5 与 ground truth 不一致(Response 2 的评分过高),因此该轨迹被拒绝。 采样3(提示采样,先说明Response 1更好): 原则: - 内容深度(权重:60%):响应是否深入解释了机器学习。 - 示例有效性(权重:40%):示例是否有效帮助理解。 评论: - Response 1:内容有一定深度,示例有效。 - Response 2:内容浅显,无示例。 预测奖励:Response 1: 评分8, Response 2: 评分2 与 ground truth 一致,因此该轨迹被保留。 1. 采样2的结果和ground-truth不一致,所以被拒绝 2. 采样1和采样3正确,但采样2错误,说明这个数据是比较难的数据(如果都对了,就太简单了,要去掉) 最终,采样 1 和采样 3 的轨迹被保留,采样 2 的轨迹被拒绝。保留的轨迹将用于训练 GRM。
Rule-Based RL
作者根据rule-based outcome rewards,采用GRPO来在线训GRM。在Rolling out阶段,模型首先生成principles和打分,然后根据accuracy rules来给rewards,具体来说:
- 对于多个response的场景($n \geq 2$),如果模型生成的点式奖励能够正确识别最佳响应(即 $S_j > S_i$),则奖励为 1;否则为 -1。
- 对于单个response的场景:如果模型生成的奖励 $S_1$ 等于 ground truth 奖励 $r_1$,则奖励为 1;否则为 -1。
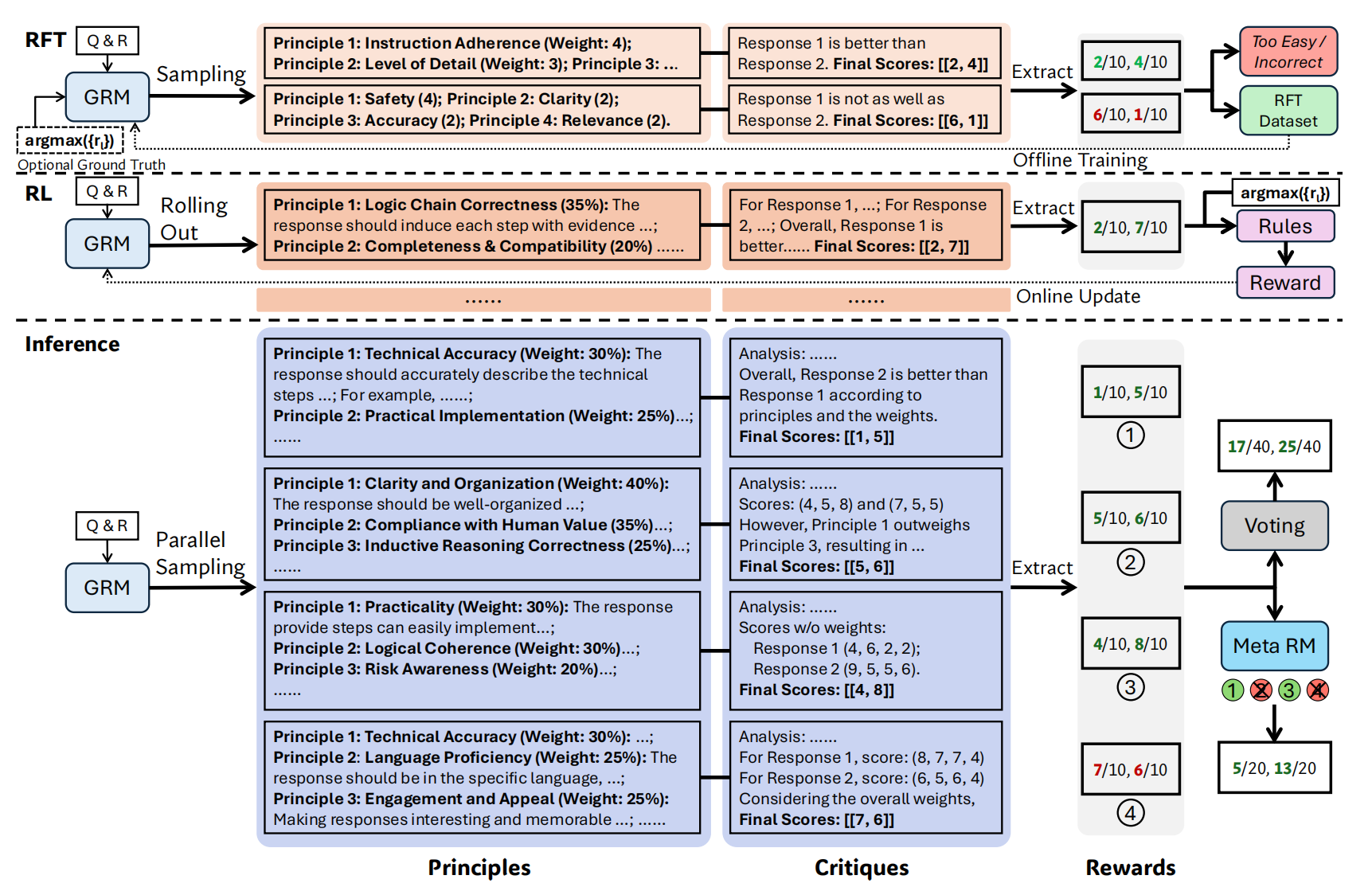
2.3. Inference-Time Scaling with SPCT
为了利用更多的推理计算资源提升 DeepSeek-GRM 的性能,作者提出了基于采样的推理时扩展策略,具体包括以下两种方法:
Voting with Generated Rewards
通过并行采样K次,DeepSeek-GRM 生成多组原则和相应的批评,然后对最终奖励进行投票。投票过程通过对每个响应的奖励求和来扩展奖励空间,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
步骤1:获取采样 采样 1: - 原则:清晰度 (40%)、相关性 (30%)、细节程度 (30%) - 批评:Response 1 清晰但缺乏细节,Response 2 相关性高且较详细 - 奖励分数:Response 1: 6, Response 2: 8 采样 2: - 原则:指令遵循度 (50%)、实用性 (30%)、语言流畅度 (20%) - 批评:Response 1 部分遵循指令但不够实用,Response 2 指令遵循度高且实用 - 奖励分数:Response 1: 5, Response 2: 7 采样 3: - 原则:准确性 (40%)、完整性 (35%)、表达方式 (25%) - 批评:Response 1 准确性一般且不完整,Response 2 准确且表达较好 - 奖励分数:Response 1: 4, Response 2: 6 步骤2:计算奖励 - Response 1 的最终奖励分数: 6 (采样 1) + 5 (采样 2) + 4 (采样 3) = 15 - Response 2 的最终奖励分数: 8 (采样 1) + 7 (采样 2) + 6 (采样 3) = 21 根据最终奖励分数,Response 2 的分数 (21) 高于 Response 1 的分数 (15),因此 Response 2 被认为是更好的响应。
Meta Reward Modeling Guided Voting
由于多次采样可能生成一些有偏见或低质量的原则和批评,作者训练了一个Meta RM来指导投票过程。Meta RM 是一个pointwise标量奖励模型,训练目标是识别 DeepSeek-GRM生成的原则和批评的正确性。Meta RM为每次采样输出一个Meta Reward Score,表示该采样的质量高低,分数越高表示采样结果越可信。
例子:
1 2 3 4 5 6 7 8 9 10 11 12
采样 1:Response 1: 6, Response 2: 8 采样 2:Response 1: 5, Response 2: 7 采样 3:Response 1: 3, Response 2: 4 采样 4:Response 1: 7, Response 2: 9 Meta RM对上面的进行分析: 采样 1:Meta Reward Score = 0.85(高质量) 采样 2:Meta Reward Score = 0.78(高质量) 采样 3:Meta Reward Score = 0.32(低质量) 采样 4:Meta Reward Score = 0.91(高质量) 假如阈值时0.8,那么只有采样1和采样4会放入其中,最终奖励为: Response 1 的最终奖励分数:6 (采样 1) + 7 (采样 4) = 13 Response 2 的最终奖励分数:8 (采样 1) + 9 (采样 4) = 17
Meta RM怎么训的:基于 Gemma-2-27B 训练,训练数据包括 RFT 阶段的轨迹和 DeepSeek-GRM 的额外采样数据。
整体来看,推理阶段拓展其实就是:
- 多次采样,生成多个原则 + 批判 + 分数;
- 对每个回答的分数做累加或聚合;
- 再引入一个 Meta Reward Model,评估每次采样的质量,挑掉那些”胡说八道”的批判或随意原则。
2.4. 实验